

2·
9 days agoServo isn’t competing at all. Servo is an experiment
Servo isn’t competing at all. Servo is an experiment
They are quite successful with Servo. Progress is obviously slow but it always had been. What matters is that progress is happening
The corporation could hire them directly
The wikimedia foundation as a nice fraction of a billion dollars in stocks in order to not rely on donations

Wait they still had employees?
Then you would understand. Even if you are benevolent, your account existing in russia is a threat to Linux
I think it should be rephrased. 95% of people on lemmy.ml are probably sane, but since all their moderators are insane, it makes it look like everyone there agrees with them
It could have worked. It was worth trying
It is actually possible to block an instance with your account. I heard Voyager and vanilla Lemmy allow this
Why would you like your IP to change? My ISP never changed mine and I thank them for that
Chinese tech leader wants west to slow down their progress on AI
They would be forced to delete all messages of all deleted users

In France you can just pick up condom packs for free at any drug store if you are under 26

Because someone’s watching you with a gun to your head. Deserting is hard

Sometimes you can’t

I think there was an officially-lead attempt to distribute internet archive over IPFS but I’m not sure what it became
Premium features for free. There are no benefits in relying on a third-party
Maybe he should focus on maintaining peace if he doesn’t want his own country to turn into bloody ashes









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
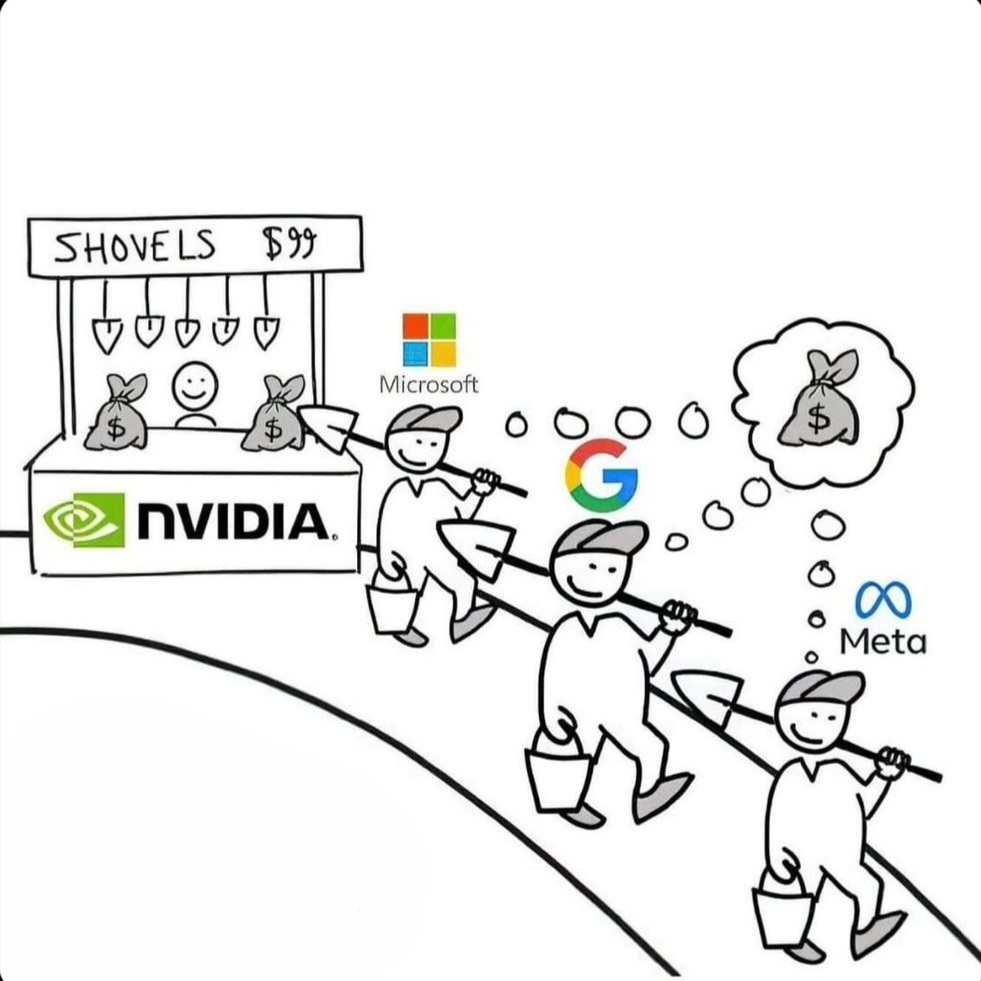{kind=link}
{kind=link}
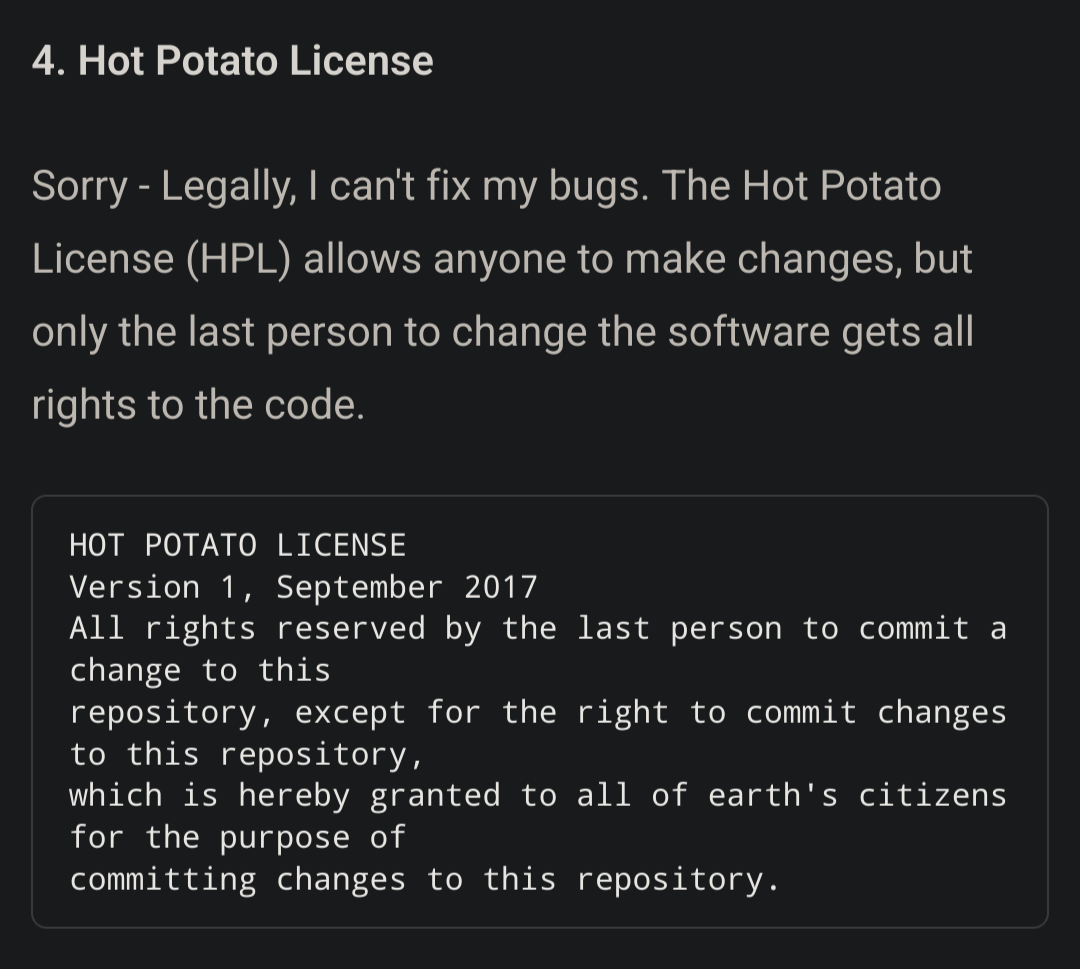{kind=link}
{kind=link}
{kind=link}
{kind=link}
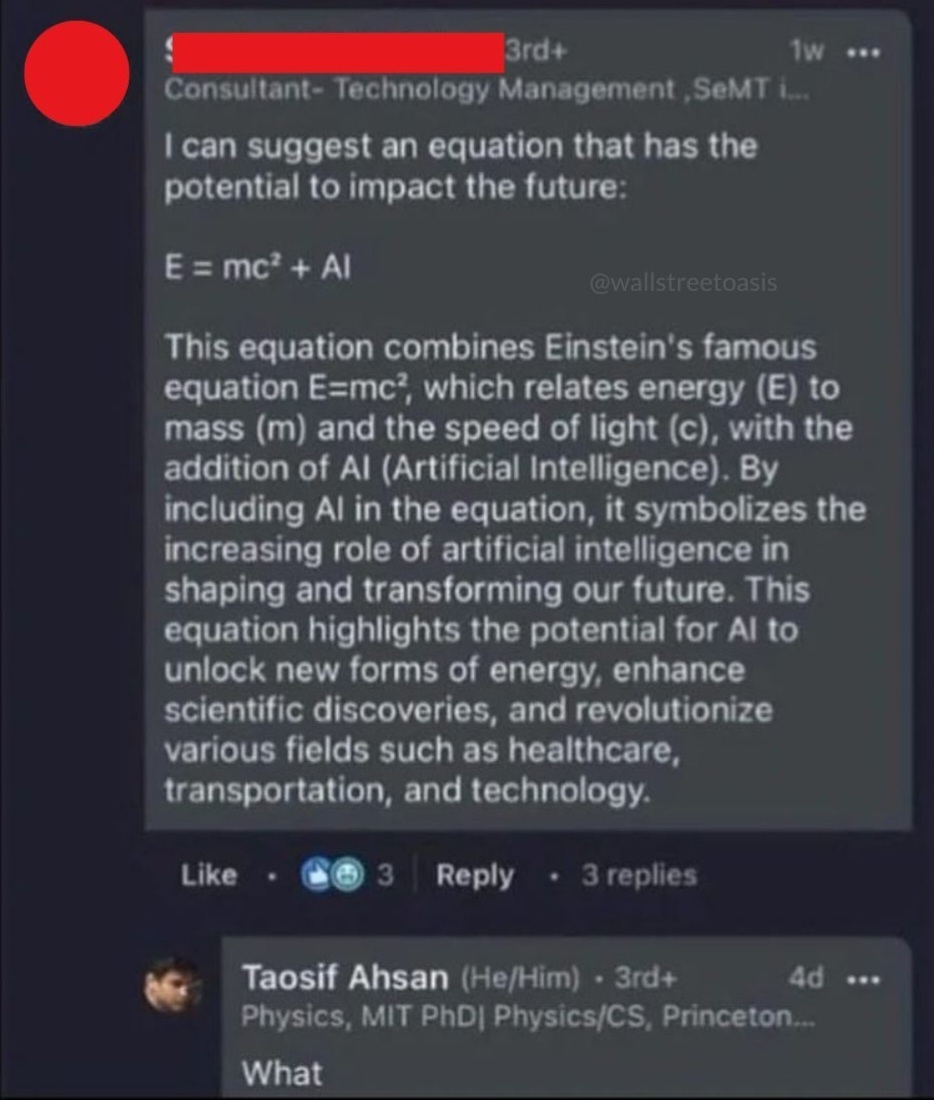{kind=link}
{kind=link}
Many other countries provide them weapons